Seeding data
Introduction
If you just installed TRAX LRS, your LRS is empty and there is no data to explore. However, you can create some fake data very easily to make some tests. In order to do that, you can create and manage seeding jobs.
Creating an seeding job
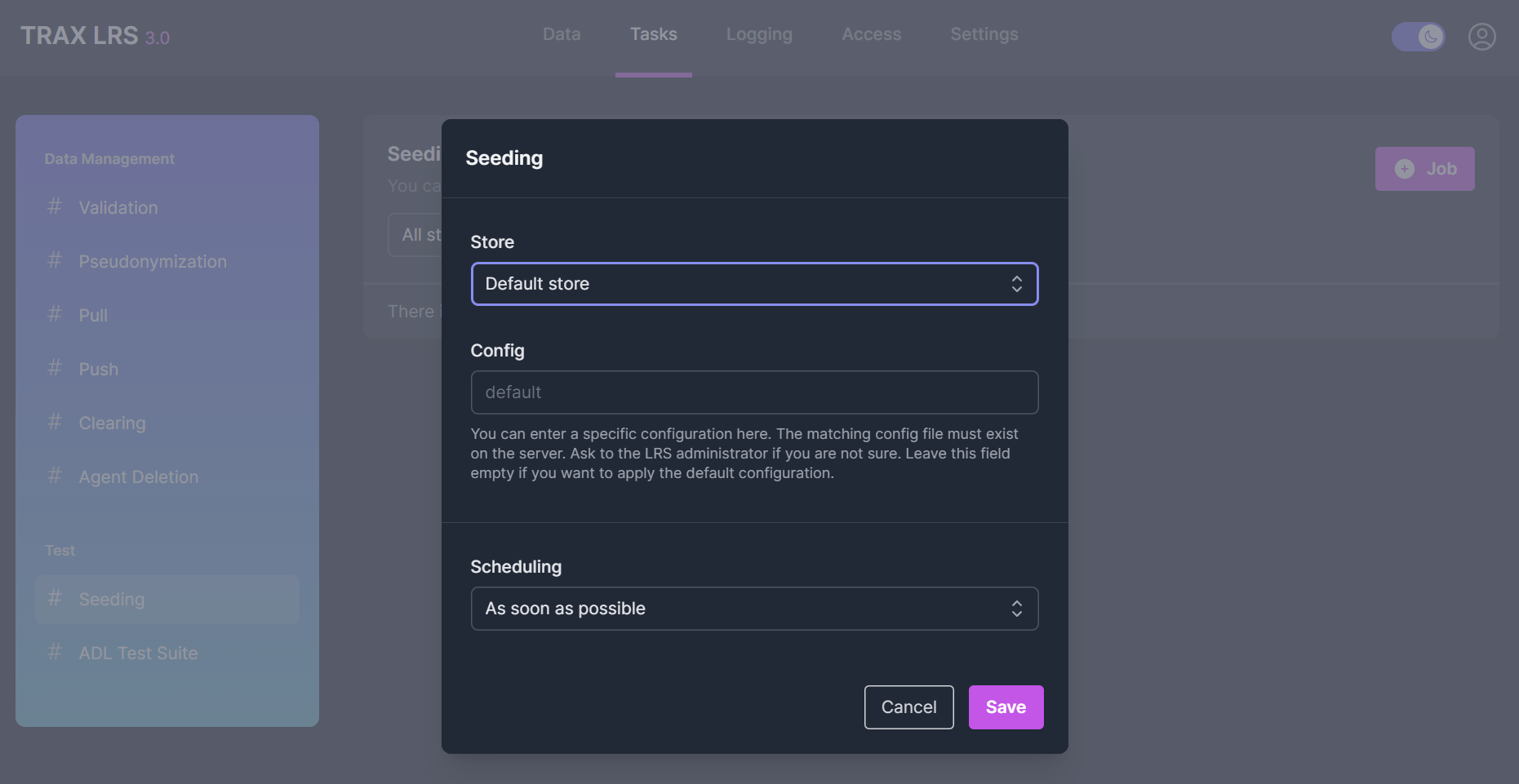
From the Tasks > Seeding page, you can create a seeding job for each store.
Optionally, you can specify a custom seeding configuration.
If no custom configuration is specified, the default configuration will apply.
Managing seeding jobs
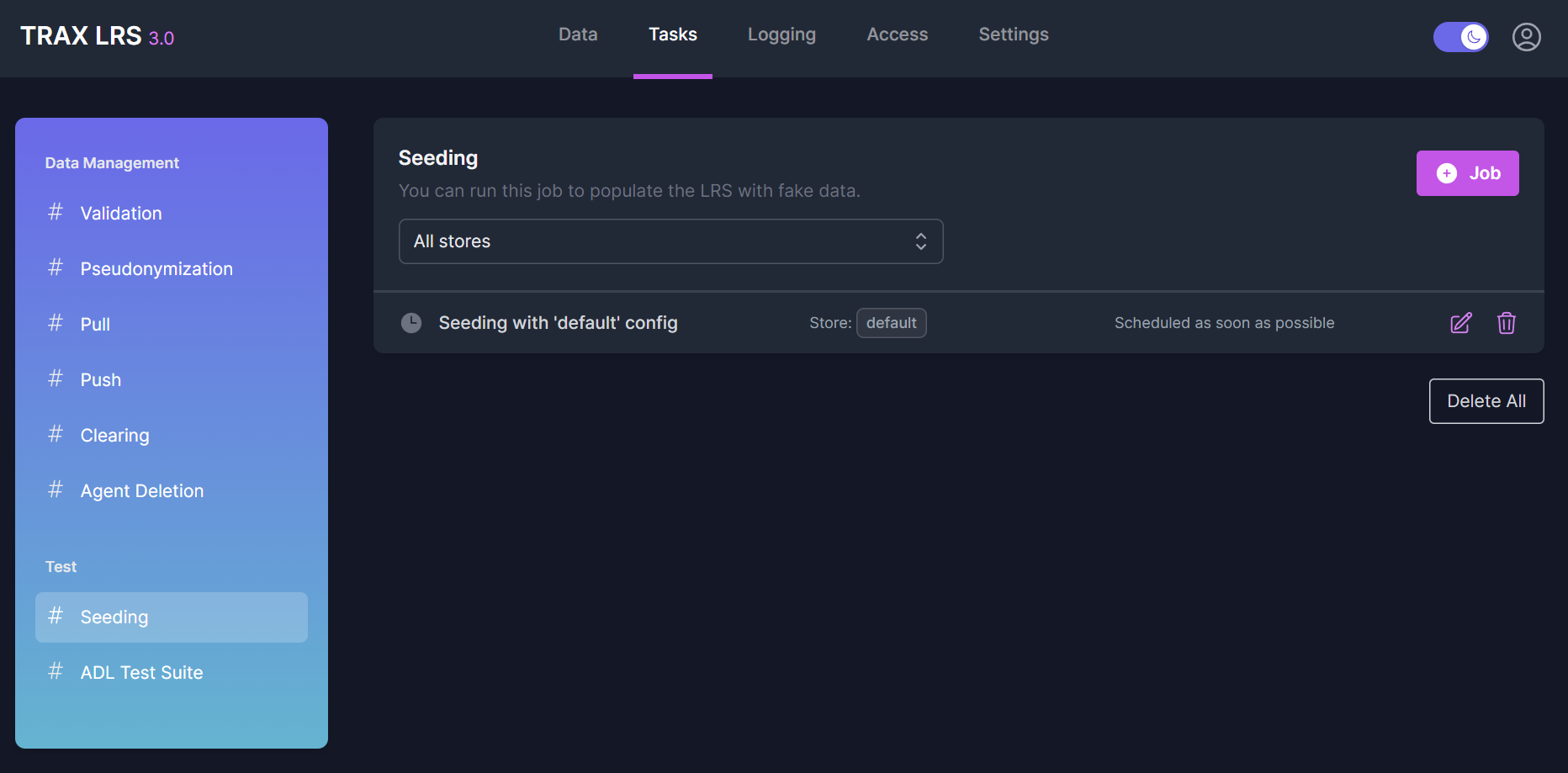
From the Tasks > Seeding page, you can see all the seeding jobs, their status and their scheduling.
You can modify, replay or delete seeding jobs.
Defining a custom seeding configuration
You can create custom configuration files in the /custom/seeding folder of the application.
Each configuration file must have the .php extension.
The rest of the file name will be used when specifying the configuration to apply.
For example, if you created a file named /custom/seeding/small-dataset.php,
you will enter the name small-dataset when creating the seeding job.
Now, let's see how to write a seeding configuration file...
Context
The xAPI context is a set of agents, groups, verbs and activities which will be used to generate statements. For each of these concepts, you can define several families with their caracteristics and a number of occurences to be generated. Let's take the default configuration file as an example:
<?php
return [
...
'context' => [
'agent' => ...,
'group' => ...,
'verb' => ...,
'activity' => ...
]
...
];Agents: we define a single agent family named default, including 100 agents with the mbox, openid or account formats.
'agent' => [
'default' => [
'number' => 100,
'type' => ['mbox', 'openid', 'account'],
],
],Groups: we define a single group family named default, including 20 groups with the mboxformat and 5 members which are agents of the default family.
'group' => [
'default' => [
'number' => 20,
'type' => ['mbox'],
'members' => 5,
'family' => 'default',
],
],Verbs: we define a single verb family named default, including 4 verbs listed below.
'verb' => [
'default' => [
'in' => [
'http://adlnet.gov/expapi/verbs/initialized',
'http://adlnet.gov/expapi/verbs/completed',
'http://adlnet.gov/expapi/verbs/passed',
'http://adlnet.gov/expapi/verbs/failed',
]
],
],Activities: we define 2 activity families named default and profile.
The first one includes 100 activities with one of the 3 types defined below.
The second one includes 3 activities with the type defined below.
'activity' => [
'default' => [
'number' => 100,
'type_in' => [
'https://w3id.org/xapi/cmi5/activitytype/block',
'https://w3id.org/xapi/cmi5/activitytype/course',
'https://w3id.org/xapi/cmi5/activitytype/lesson',
],
],
'profile' => [
'number' => 3,
'type_in' => [
'http://adlnet.gov/expapi/activities/profile'
],
],
],Templates
Before generating data, you must define data templates for the statements, states, agent profiles and activity profiles. For each of these concepts, you can define several templates by specifiying the data structure and some rules to populate properties. Let's take the default configuration file as an example:
<?php
return [
...
'templates' => [
'statements' => ...,
'states' => ...,
'agent_profiles' => ...,
'activity_profiles' => ...
]
...
];Statements: we define 1 template named default, with several concepts injected from the context:
an agent from the default family as the actor, a verb from the default family,
a group from the default family as the context team, activities from the default and profile families
as the context parent and category. Several properties have a generated value, prefixed by faker:.
'statements' => [
'default' => [
'actor' => 'agent::default',
'verb' => 'verb::default',
'object' => 'activity::default',
'result' => [
'completion' => 'faker::boolean',
'success' => 'faker::boolean',
],
'context' => [
'registration' => 'faker::uuid',
'team' => 'group::default',
'contextActivities' => [
'parent' => ['activity::default,compact'],
'category' => ['activity::profile,compact'],
],
],
],
],States: we define 2 templates named elearning-status and feedback.
Both templates are associated with activities and agents from the default family.
The first one has a application/json MIME type. The second one has a text/plain MIME type.
Both templates have contents which include properties with generated value, prefixed by faker:.
'states' => [
'elearning-status' => [
'agent_family' => 'default',
'activity_family' => 'default',
'mime_type' => 'application/json',
'content' => [
'current-page' => 'faker::randomDigit',
'language' => 'faker::languageCode',
'audio' => 'on',
],
],
'feedback' => [
'agent_family' => 'default',
'activity_family' => 'default',
'mime_type' => 'text/plain',
'content' => 'faker::sentence',
],
],Agent profiles and activity profiles have very similar templates.
Dataset
Finally, you can define the number of concepts to be generated for the overall dataset, including statements, states, agent profiles and activity profiles. Let's take the default configuration file as an example:
<?php
return [
...
'dataset' => [
'statements' => [
'default' => 1000,
],
'states' => [
'elearning-status' => 100,
'feedback' => 100,
],
'agent_profiles' => [
'learner-preferences' => 100,
'biography' => 100,
],
'activity_profiles' => [
'competency-mapping' => 100,
'summary' => 100,
],
],
...
];The dataset will include 1000 statements from the default family,
100 states from the elearning-status family,
100 states from the feedback family,
etc.
Options
Some optional features are also available in the options section.
Let's take the default configuration file as an example:
<?php
return [
...
'options' => [
'persons' => [
'enabled' => true,
'agents_per_person' => 3,
],
],
...
];The persons is enabled in order to generate persons with 3 agents per person.